基于VIPS的网页分块算法
VIPS(VIsion-basedPage Segmentation)基于视觉的页面分块算法,由微软研究院的Cai Deng等人于2003提出来的. 它利用Web页面的视觉提示如背景颜色,字体颜色和大小,边框,逻辑块和逻辑块之间的间距等,结合DOM树进行页面语义分块,并把它应用TREC2003 的评测中,取得了较好的效果.
VIPS 算法中首先定义了"基本对象"的概念,通常 DOM 树上的叶子结点被定义为基本对象,因为这些结点已经不能再被继续分割了.VIPS 中引入了基于视觉的内容结构,它里面的每一个结点称之为”页面块”,这些块或者是一个基本对象或者是一些基本对象的组合.有一点需要注意的是,基于视觉的内容结构中的块与 DOM 树中的结点没有绝对的对应关系.
VIPS 算法中 Web 页面的视觉结构定义如下: 将网页看作一个三元组Ω=(Ο,Φ,δ),其中Ο=(Ω1,Ω2,…Ωk),表示给定页面上的所有的语义块的集合,这些语义块之间没有重叠覆盖,而每一个语义块Ωi又可以被定义为前面所描述的三元组Ωi=(Οi,Φi,δi),如此迭代循环;Φ=(Φ1, Φ2,…ΦT),表示当前页面上的所有的分隔条的集合.事实上,一旦确定了一个页面上的两个语义块,那么这两个语义块之间的分隔条也就被确定了.当然,VIPS 中的分隔条并不是真正存在的分隔条,而是虚拟.分隔条包括水平分隔条,也包括垂直分隔条.每一个分隔条都具有一定的宽度和高度.δ=(ζ1,ζ2,…,ζm)则描述了Ω集合中两个语义块之间的关系,这种关系可以用下面式子描述:δ=Ο×Ο→Φ∪{NULL}.其中每个ζ都是一个形如(Ωi,Ωj)二元组,其表示块Ωi和Ωj之间存在一个分割.
VIPS具体有三个步骤:页面块提取,分隔条提取,语义块重构,这三个步骤联合一起作为一次语义块检测的完整步骤.
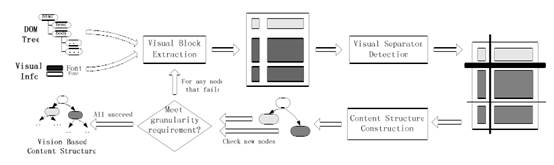
1) Web 页面首先被分割为几次比较大的语义块,同时这几个语义块所组成的层次结构将被记录下来.对于检测出来的每一个大的语义块分块过程又可以继续进行,直到语义块的DoC(Degree of Coherence) 值达到预先设定PdoC (Permitted Degreeof Coherence)为止.在每次迭代循环中,当前逻辑块的 DOM 树结构以及它的视觉信息都将被获取.
2)然后,从 DOM 树的根结点开始,逻辑块检测过程将基于视觉信息开始从DOM 树中开始检测页面块.每一个 DOM 结点都会被检查它能够构成一个单独的页面块.如果不能,那么它的子结点将被执行同样的检查.对于每一个提取出来的页面块,我们都会根据当前页面块的内部可视属性赋予一个 DOC 值.当本次迭代过程中所有的页面块都被检测出来之后,它们将被保存到页面块池中.
3)基于这些页面块,分隔条检测过程将开始工作.这些页面块之间的所有的水平分隔条和垂直分隔条最终将被识别出来并且赋予一定的宽度和高度.基于这些分隔条,页面的布局层次将被重新构建——一些页面块将被合并,形成语义块.
4)最终,本次迭代过程中的所有语义块都被检测出来. 迭代过程是否需要继续进行取决于本层次的语义块中是否存在DOC 值小于 PDOC 的语义块.对于那些DOC >= PDOC的语义块,分隔过程将停止,否则分隔过程将继续.当所有的语义块被提取出来后,最终整个Web 页面的基于视觉的内容结构也就构建完成.
VIPS 在网页块提取时对 DOM 树中的每一个节点进行检查,网页块提取的规则多达 13 条,导致网页块提取过程非常复杂,性能不高.而且随着互联网的深入发展,网页格式越来越复杂,规则并不能完全适用.
参考文献
[1] Cai D,YuS,Wen JR,etal. VIPS:A visionbased page segmentation algorithm. Microsoft Technical Report,MSR-TR- 2003-79,2003:10.
